Some preliminary comments:
I wrote this page a couple of years ago for MAT390H1 - History of Mathematics before 1700. As such, it focused on entering a handful of numbers in hieroglyphics or cuneiform. It was also designed to highlight some of the reasons that UNICODE handles hieroglyphics and cuneiform very differently from cyrillic, Greek or other European character sets. It only addresses the problem of entering large amounts of text tangentially.
To be honest, most of the techniques covered by this page are quite impractical. I think that they may be useful to anyone who needs to work with these character sets programmatically, however. I have created a separate page that addresses approaches to entering larger volumes of hieroglyphic text.
I am leaving this page up, however, because (1) almost all discussions of UNICODE pretend that only Plane 0 exists(Cuneiform and Hieroglyphic characters are on Plane 1), and (2) it will continue to provide an understanding "close to the metal" of what powerful tools like JSesh, and implementations of MdC and RES are actually dealing with under the covers.
Introduction
With the adoption of the UNICODE Standard, using modern languages written in non Latin alphabets on computers has become easy and commonplace. This is not quite the case for Egyptian Hieroglyphics and Babylonian Cuneiform. Although they are supported by UNICODE, for technical reasons the support is not as seamless as for Greek, Russian, Japanese, Chinese, Korean... Displaying characters is generally simple, but entering them into an application can be tricky. The purpose of this page is to explain how you can display and enter Hieroglyphics and Cuneiform into documents, web pages and Latex documents.
As Cuneiform is handled by most applications identically to Hieroglyphics, I will generally just refer to Hieroglyphics going forward unless there is a specific reason for making a distinction.
As you will shortly see, parts of this are very ugly. The last part of this page provides some historical and technical information that explains this.
For your convenience, here are links to the Unicode documents that describe all of the Unicode characters, show a glyph for each one, and provide the offical name of the character:
- Unicode: General Discussion of Hieroglyphic and Cuneiform Character Support
- Unicode: Hieroglyphics Character Charts
- Unicode: Cuneiform Character Charts
1. Displaying Hieroglyphics/Cuneiform on the screen or printer
My experience has been that Microsoft Office, browsers(Safari, Chrome, Firefox, Edge), text editors(Visual Studio Code, TextEdit, Xcode, Sublime Text, Atom, MS Notepad, Notepad++), and office applications(MS Office, LibreOffice) will do a good job of finding the appropriate glyph and displaying the characters with no extra work on your part. For the non-browsers, you might need to make sure that you have an appropriate font installed, and directed to the text in question.
I have found the following fonts to work well for Cuneiform and Hieroglyphics.
| Font | Cuneiform | Hieroglyphics | Comments |
|---|---|---|---|
| Noto Sans EgyptHiero | No | Yes | I highly recommend the Noto fonts from Google. Over 75 of them, covering pretty much the entire Unicode codespace can be downloaded as a single package from Google Noto Fonts. They can be installed on Windows and Mac |
| Noto Sans Cuneiform | Yes | No | |
| Segoe UI Historic | Yes | Yes | This is the fallback font for ancient languages on Windows 10. The only concern for us is that it is missing the glyph for U+12399 - the Cuneiform for 20 (𒎙). Go figure. Other than this, Segoe UI Historic is a nice font, and it supports a lot of obscure codepoints. If you have MS Office on Mac, you should also have this font. |
| Aegyptus | No | Yes | Nice Hieroglyphic font. It is shipped as part of the Keyman Egyptian Hieroglyphic keyboard IME (discussed later). |
2. Entering Hieroglyphics/Cuneiform into an application
There are several different approaches that you can use to enter hieroglyphics or cuneiform into an application. The approaches fall into the following groups:
- Approach 1: Cutting/copying existing text to the clipboard and pasting it into another application. (Very easy and intuitive - but it assumes that you have the desired hieroglyphic character on the screen in an application that allows you to copy it to the clipboard.)
- Approach 2: Using a keyboard template that is designed to input the characters efficiently. These usually also include a "character picker" function that will display a list of characters and allow you to select one. (Easy to use. Does not require any deep technical skill. It does require that you install the keyboard manager and an appropriate hieroglyphic keyboard template.)
- Approach 3: Directly entering a Unicode value in hexadecimal or decimal. (Very unfriendly! Involves finding the actual hexadecimal/decimal code for the character you want. Very tedious for entering anything more than a handful of characters.)
Approach 1: Cut and paste via the clipboard - Works on Mac and Windows
Let's assume that you have some Hieroglyphics characters displayed on the screen. It could be in a browser page, in a PDF, in a spreadsheet, etc. Select the desired text, cut or copy it to the clipboard, and paste it into your document. In particular, this means that you could use something like my Egyptian and Babylonian Number Tools to generate a hieroglyphic number and then use the clipboard to paste it into some other document. This approach seems to work in most applications on both Windows and Mac. (Of course, this does assume that you actually have some existing text that you can copy to the clipboard!)
Approach 2: Using a keyboard template designed for the language of interest
From a user point of view, this is the cleanest approach to generating characters. Like a keyboard template for English, German, Chinese, it is set up to efficiently allow you to enter text.
I have created a special Keyman keyboard template for cuneiform and hieroglyphic numbers. For example:
- Cuneiform: You enter 192 (3,12) as ;3␢␢;[Shift]+1;2, producing 𒐗 𒌋𒐖. (␢ = [SPACE])
- Hieroglyphics: You enter 304,168 as ;p8;o6;i1;u4;t3 , producing 𓐁𓎋𓍢𓆿𓆐𓆐𓆐. (Remember, we want units first.)
Keyman is open source and will run on both Windows and Mac. To use it, you will need to:
- Install Keyman Desktop and then
- download my cuneiform and hieroglyphic numbers keyboard template. Double Click on the cuneiform_numbers.kmp file to install it. The package has documentation on how to use the keyboard.
- Enable the Keyman keyboards
I have found two other ways to access a keyboard that directly supports hieroglyphics (but not cuneiform). There is a website called the Egyptian hieroglyphic character picker. It is very good, but again, it assumes that you have access to a list of the "Gardiner" or "Manuel de Codage(MdC)" codes.
Finally, there is a tool called JSesh: An Open Source
Hieroglyphic Editor. It is very powerful. In particular, it
allows you to to position individual characters relative to each other in different ways(quadrats) and
create cartouches. For example, I created the
cartouches of Pharaohs Tutankhamun  and
Khufu
and
Khufu
 shown at the top of this page in a
couple of minutes using this tool.
Again, you need to have access to a list of the "Gardiner" or "Manuel de Codage(MdC)" codes. Also, it
outputs images, rather than Unicode characters, which could be problematic for inclusion in a text
document.
shown at the top of this page in a
couple of minutes using this tool.
Again, you need to have access to a list of the "Gardiner" or "Manuel de Codage(MdC)" codes. Also, it
outputs images, rather than Unicode characters, which could be problematic for inclusion in a text
document.
The Keyman Egyptian Hieroglyphic keyboard template, the Egyptian hieroglyphic character picker website, and the JSesh Editor all provide a "character picker" capability. My Cuneiform and Hieroglyphic Numbers Keyboard does not have this capability, but given its limited focus (just numbers) it wouldn't really add any useful function.
Other than my Keyman keyboard template (which only supports numbers) I have not found a keyboard template that supports the entry of cuneiform characters.
Approach 3: Direct hexadecimal/decimal entry of the Unicode - Different approaches for Mac and Windows
If none of the above approaches will work for you, you will need to manually enter a Unicode character code into your document. Frankly, this gets really ugly really fast. For example, to enter the hieroglyph for 1,000 (𓆼), you will need to key in one of 131BC16, D80C16DCAD16 or 7799710 - which one depends on your platform and application. 😢
The process of directly entering the codepoint into an application is quite different for Mac and Windows. I will provide details on one approach for Mac(3a), and two on Windows(3b-i and 3b-ii).
3a) Mac: Direct entry of unicode codepoints in hexadecimal
For this technique, you will enter 8 hexadecimal digits to identify the character you want while holding down the "Option" key.
We will need to enable Apple's "Unicode Hex Input Source" before we begin, but don't worry, there is nothing to download and it will only take a minute. The reason that we need to do this is that by default Macs support entering some special characters via the option key. Try it: Hold down the Option key and press the "3" key to get £. This clearly interferes with our need to enter arbitrary strings of hex digits (0123456789abcdef) with the Option key.
To install the Input source, go:
System Preferences => Keyboard => Input Sources => + at bottom
=> Scroll to bottom of list => Other => Select "Unicode Hex Input" => Click on "Add"
You will now see a new icon in the system toolbar. Click on it and select "Unicode Hex Input". (You can follow this process to switch back to your original keyboard later.)
Now, we want to put a hieroglyphic into a file. First, open an editor, Word or Excel and a document to receive your characters. I have created two reference pages on this site that will provide you with the proper codes that you will input:
Here is a snippet from the Egyptian page. We are going to put the character for 2,000 (𓆽) into your document.
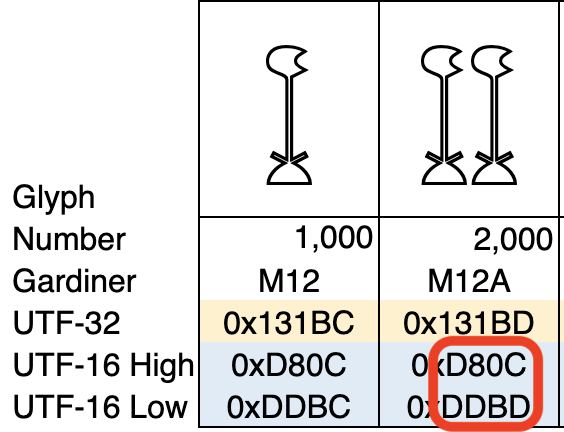
We are interested in the UTF-16 High and UTF-16 Low values (in the red box). They are known as a "UTF-16 surrogate pair". While holding down the Option key, type in d80cddbd and then release the Option key. A glyph showing two lotus flowers will appear in your document. You can then change its colour, size etc. as you normally would.
Note: Don't worry about the 0x's in the snippet. They just indicate that the following strings of characters are in hexadecimal notation. You don't type the 0x. Also, you can type the alpha characters in lower case, even though the snippet formally shows them in upper case. If you are interested in what all this means, and what UTF-32 and UTF-16 are, see Section 4 on Technical Background, below.
Note: There are now browser based versions of the Microsoft Office applications. They support the cut and paste approach described above and they display the characters, but I have not been able to use them to directly enter hex values. You will need to use the version of the application that is downloaded and actually runs on your Mac.
Note: LibreOffice does not support entering hieroglyphics using this approach.
Note: This technique will also work with non Hieroglyphic or Cuneiform characters. In those cases, you will typically just need to type 4 hex digits, which will correspond to the character's codepoint. (This is because most non hieroglyphic/cuneiform characters that you will be interested in are in Unicode Plane 0. See the technical discussion below for more context on this statement.) You will need to determine the Unicode codepoint for the character you want, of course. This information is available on the tables indexed by the Unicode Character Code Charts webpage.
3b) Windows: Direct entry of unicode codepoints in hexadecimal/decimal
This section assumes that you have read the above section on entering characters on Mac, as it will only cover the mechanics of actually entering the digits on Windows.
Unlike Mac, where there is a global unicode input source which works across all applications, support for unicode seems to differ from application to application. I have not been able to get it to work in Excel, Powerpoint, or editors(Notepad++, Notepad, VS Code) for characters in Plane 1. I have found two ways that work for Word, so I will cover these. You could then cut and paste your characters into another application.
3b-i) MS Word on Windows: Inputting a codepoint in hexadecimal digits (preferred approach)
In this approach, you type the 4 or 5 hex digits representing the codepoint (the UTF-32 value shown on my Hieroglyphic and Cuneiform pages) into the document and then press Alt-x. Those digits will be replaced by the desired unicode character. For example, to get 𓁨 we type: 13068 Alt-x. This is particularly nice, because we can directly use the codepoint value from the Unicode documentation, rather than having to work out the UTF-16 values as we do on Mac.
(There is one unfortunate side effect of the way that Microsoft has designed this method. If you are entering a unicode codepoint in Plane 0, which has only 4 hex digits, and the last character that you typed before you start entering the 4 digits for your character could be concatenated with those the 4 digits describing your character to make a valid codepoint somewhere in Plane 1 to Plane 16, the system will do this. This essentially means that you cannot start a 4 digit entry immediately after any of {0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f}. For example, if you had entered 1231, and then wanted to enter 0x3068, which should produce 1231と(1231 followed by the Japanese Hiragana character for the syllable "to"), the code run by Alt-x would see the 12313068, and consume the 13068, producing 123𓁨, which is not not what you want. To avoid this, you would need to type a space before entering the code for your character. e.g 1231 3068 Alt-x) Anyone who has played around with Lisp or old HP calculators will recognize this "feature" as an artifact of Polish/prefix and Reverse Polish/postfix Notations, and the reason that Lisp has all of those parentheses that people love so much!
(- (/ (* (+ a b) (* c d)) (- (* e f) (/ g h))) (/ (* (+ i j) (* k l)) (- (* m n) (/ o p))))
3b-ii) MS Word on Windows: Inputting a codepoint in decimal digits (deprecated approach)
There is an alternative way of entering unicode characters in MS Word. I prefer the one described above, but for completeness, here is the alternative.
First, make sure that NumLock is on for the numeric keypad. First issue: This approach will not work using the numeric keys across the top of the keypad. Second issue, you need to convert the unicode codepoint from hex to decimal notation. For example, U+1306816 ==> 7792810. Finally, you type 77928 while holding down the Alt key. When you release the Alt key, the system will insert your character. Clearly, the biggest issue is in finding the base 10 value of the codepoint. All of the unicode documentation expresses codepoints in base 16. You can always use the Excel HEX2DEC formula (e.g. HEX2DEC(1230d)==> 74509, which you can use to get 𒌍), but it is pretty ugly.
3. Guidance for Specific Applications - Web pages and LaTeX
3a. Web pages: html, Javascript
You can directly enter a character into html or Javascript via cut and paste (Approach 1), a keyboard template (Option 2), Option+dddddddd (Approach 3) or by entering escape sequences directly into the source code. Approaches 1 and 2 are very clean for both html and Javascript, so I will not say anything more about them.
The approaches discussed below are very clean in html. However, Javascript is an entirely different matter. The approaches can best be described as 'quirky'. Not only are they entirely different from the html ones, but they differ from each other. If you want to use these characters in Javascript, you should go through the examples very carefully.
| Language | Entry Method | Example | Results | Comment |
|---|---|---|---|---|
| HTML | Escape sequence in html source | 𒌍 |
𒌍 | Note that the hex string we enter is the 5 hex digit Unicode codepoint. This is the value identified as UTF-32 on my Egyptian Hieroglyphic Numbers and Babylonian Cuneiform Numbers pages. |
| Option+dddddddd into html source | Option+d809dc18 |
𒐘 | Note that the hex string we enter is the 8 digit UTF-16 word pair. These are the values identified as UTF-16 High and UTF-16 Low on my Egyptian Hieroglyphic Numbers and Babylonian Cuneiform Numbers pages. | |
| Javascript | Escape sequence in Javascript source |
<td>
|
Note that the hex string we enter is the two word UTF-16 sequence. These are the values identified as UTF-16 High and UTF-16 Low on my Egyptian Hieroglyphic Numbers and Babylonian Cuneiform Numbers pages. Also, we must write out both of the UTF-16 words separately! | |
| Option+dddddddd into Javascript source |
<td>
|
Note that we simply write the variable to the document. We do not need to handle the two UTF-16 words separately. Also note that we need to enclose our character string in quotation marks, as we must enter a valid Javascript string. |
3b. LaTeX Documents
The following applies to TeXShop running on a Mac and MiKTeX running on Windows 10. Before formatting your document, make sure that you have selected the XeLaTeX engine to process your source file. XeLaTeX is an engine that has been specially enhanced to work with Unicode characters out of the box. It is now a standard part of all the standard distributions - certainly TeXShop on Mac and MiKTeX on Windows.
4 ways of entering characters into your .ltx source file in a text editor.
- Copy and paste the glyph directly into source file.(Approach 1) [I will have no further comments on this.]
- Use a language specific keyboard.(Approach 2) [I will have no further comments on this.]
- Use the Option+dddddddd method.(Approach 3) [I will have no further comments on this.]
- Use the \symbol LaTeX command to enter UTF-16 codes: e.g to enter 𓆽: \symbol{"D80C}\symbol{"DDBD}
For the \symbol approach, it is important that there be no spaces between the two \symbol strings. Also, any alphabetic characters in the hex strings MUST BE IN UPPER CASE. I have included two examples of using the \symbol approach in the sample code posted below.
Formatting your .ltx file and working with fonts
Interestingly, getting fonts to display the proper glyphs proved to be the most challenging part of the LaTeX exercise.
Google has a project called Google Noto Fonts which has over 100 free fonts. The objective of the project is to provide a consistent set of fonts that cover all languages included in the Unicode Standard. In particular, they want to focus on more obscure languages that are not covered by the big mainstream fonts. They already have rolled out Noto Sans Cuneiform and Noto Sans Egyptian Hieroglyphs. One caveat is that these fonts seem to have only the glyphs for their specific language - so you need to enable them for just the Cuneiform/Hieroglyphic text and disable them before printing any text in another language. This is not a problem in LaTeX, as I used the fontspec package, which makes it very easy to turn a specific font on or off.
Below is a complete source file. You should be able to select all of it, copy it into an empty file, save it with a .ltx extension and feed it to XeLaTeX. It assumes that you have installed the Noto fonts.
Here is a commentary on my markup for the sample .ltx file below:
- Setup the fontspec package: \usepackage{fontspec}
- Define a Cuneiform font: \newfontfamily\NotoCuneiform{Noto Sans Cuneiform} and call it NotoCuneiform
- Define a Hieroglyphics font: \newfontfamily\NotoHieroglyphs{Noto Sans Egyptian Hieroglyphs} and call it NotoHieroglyphs
- Insert Cuneiform/Hieroglyphic texts via 1) Cut and paste, 2) Option+dddddddd, 3) LaTeX \symbol command.
- Enable the special fonts. This is done as follows: {\FontName text_to_print_in_font }. The FontName is the name you defined in the \newfontfamily command.
Sample LaTeX source document
\documentclass[12pt]{amsart}
|
Sample LaTeX output
|
4. Some Technical Background on Unicode
Some History - Why Unicode?
Before the adoption of The Unicode Standard during the 1990's and early 2000's, it was very difficult to share documents among different countries because different standards were used to represent individual characters in each language. For European languages, each character was represented by a single 8-bit byte, so that a maximum of 256 different characters could be represented. Actually, many fewer were available for local customization, since the first 128 were typically the same for everyone - the ASCII characters containing English capitals, small letters, numbers, control characters, basic punctuation and symbols. Each "codepage" would customize the second 128 codepoints to its own need for accented letters, non-English letters, local punctuation marks, etc.
There were literally hundreds of codepages: US ones, Local Western European ones, generic European ones, Canadian ones, Russian ones, Greek ones, etc. Because they were all redefining the same 128 points, a given hex value might mean Ë in one codepage, but Щ, Ψ, or Ø in others. This was fine as long as a document written on a computer in Russia was read on another computer in Russia, but if it was sent to someone in Greece, it would look like gibberish. In the case of East Asian Languages (Chinese, Japanese, Korean - CJK) which had thousands of different characters, many mutually inconsistent "double byte" or "multibyte" encoding schemes were developed - not just with different definitions of codepoints, but with different approaches to their underlying structures. It was a real mess, and by the 1980's the growth in the number of documents that needed to be shared around the world meant that something needed to be done. The result was to create a new universal standard for character representation that would contain all of the characters from all of the languages on the planet - The Unicode Standard.
The first version of Unicode was published in 1991. It defined each codepoint with two bytes (16 bits), theoretically supporting 64K unique characters to allocate among the languages of the planet. This was soon found to be inadequate, and in the mid 1990's the standard was revised allowing for 20 bit character id's. It supports 1,111,998 potential characters and the current version (Version 13.0 as of mid 2020) has 143,859 codepoints actually assigned. Incidentally, this bit of history is why, even today, you will hear people refer to Unicode as a "double byte" encoding, and why many still mistakenly believe that Unicode only supports 64K characters.
An Overview of How Unicode Works
Abstract Characters, Codepoints, Encoded Characters, Planes
I need to begin by saying that this is an extremely high level view of Unicode. I gloss over many topics and ignore many subtleties. This is a fascinating subject, and there is an enormous amount of documentation on the Unicode Standard website.
Unicode maps every abstract character(A,B,C,1,2,3,=,$,Ы,𓁨,𒌍...) to an integer in its codespace, which is the interval [0x000000, 0x10FFFF]. These integers are referred to as codepoints. So, abstract characters are assigned to individual codepoints. The proper way to indicate a Unicode codepoint is U+[4 or 5 hexadecimal digits]. See the first column of the table below. A character assigned to a codepoint is called an encoded character. For example:
| Codepoint | Char | Official Unicode Name | Plane | Offset within Plane |
|---|---|---|---|---|
| U+0062 | B | LATIN SMALL LETTER B | 0 | 0x0062 |
| U+042B | Ы | CYRILLIC CAPITAL LETTER YERU | 0 | 0x042B |
| U+13068 | 𓁨 | EGYPTIAN HIEROGLYPH C011 | 1 | 0x3068 |
Almost all of the characters used on a daily basis in modern languages are part of Plane 0. They are identified by a 4 hex digit code. This is important because application designers can support the vast majority of users without ever worrying about the more complex handling of Planes 1-16. A study by the Unicode Consortium in 2009 found that 87% of the characters used were Latin or Cyrillic letters, numbers or punctuation. I expect that this number will have dropped quite a bit in the last decade, as many organizations using CJK languages have converted from the myriad Chinese, Japanese and Korean encoding schemes to Unicode. Nevertheless, the vast majority of characters used are from Plane 0. Remember that the Unicode Hex Input Source did not allow us to directly enter the 5 hex digits that identify Hieroglyphic/Cuneiform characters. Rather, we had to enter two 4-hex digit numbers. (Their origin will be discussed below.)
Encoded Forms - UTF-32, UTF-8, UTF-16<== go to page 26 of this document for a detailed discussion of encoded forms
The encoded characters described above do not represent the way that characters are actually stored in computer memory or storage. Unicode defines three Encoded Forms for actually storing characters: UTF-32, UTF-8 and UTF-16. Let's examine each of these, as they throw light on how we entered Hieroglyphic and Cuneiform characters.
UTF-32
UTF-32 is the easiest to explain. It directly maps the Unicode codepoint to a 32 bit string. It takes the codepoint and left pads it with zeros. Thus B (U+0062) becomes 0x00000062, and 𓁨 (U+13068) becomes 0x00013068. One of the great advantages of UTF-32 is that once a character is encoded in it, the application does not need to perform complicated calculations in order to use it. It can directly lookup the appropriate glyph from a table, for example. Additionally, most Unicode documentation identifies characters by their U+xxxxx codepoint, which is effectively the UTF-32 encoding. On the other hand, UTF-32 is very wasteful of space. Consider a string that is composed of ASCII characters. In UTF-32 each character takes up 4 bytes, but three of them are zeros. Similarly, other characters in Plane 0 need 2 bytes to describe them, and so 2 bytes are wasted for each one. Each character in Planes 1-16, e.g. 𓁨 (U+13068), takes up 32 bits, when only 20 are really needed to represent the character. (While this may not be as critical as it was on some of the first machines that I worked on in the 1970's with only 4 KB of memory and 5.0 MB of disk storage, it is still very wasteful!) UTF-32/the Unicode codepoint is the source of information that was used to enter values into Windows in Methods 3b-i and 3b-ii in Section 2 of this webpage.
UTF-8
UTF-8 is probably the encoded form that you have encountered in the past. It is the current standard format for saving files to disk or the cloud and it is also the standard encoding format for web pages. UTF-8 stores each character in from 1 to 4 bytes. UTF-8 takes advantage of the huge preponderance of ASCII characters in Western Languages, for which it only uses a single byte. Other codepoints in Plane 0 require 2 or 3 bytes and codepoints in Planes 1-16 require 4 bytes. Thus UTF-8 requires substantially less storage than the other forms for Western languages, although it requires more than UTF-16 for CJK languages and Hindi. The algorithms used to convert from the codepoint(U+xxxxx) to UTF-8 and back are non trivial. Because characters are of variable length, programs need to do more post-processing of a UTF-8 string than they do with fixed length UTF-32 encodings. None of the methods for inputting characters discussed on this page use UTF-8 directly.
UTF-16
Like UTF-8, UTF-16 does not intuitively map to the Unicode codepoint. It maps all characters in Plane 0 directly to the same 2 byte value as the U+xxxx codepoint value, but uses a more complicated bijection to transform all characters in Planes 1-16 to 4 bytes (2 x 2-byte-words). It is less computationally intense than UTF-8, and more storage efficient than UTF-32. In particular this ties us back to why we had to type in 8 hex digits for our Hieroglyphic character, as all characters are represented by either 4 hex digits or 8 hex digits. If you go back and look at the snippet for the lotus flower you will see that UTF-16 was the source for the data that we entered into Mac.